In this tab, we try to use ARM (Association Rule Mining). This tab researches on the account descrption written by the users who sending rumors(which is the “description” column in the “cleaned_rumor_manually.csv” data set) to find the features tell users tending to spread rumors
Theory
ARM searches for the relationship between different things, recording when items happened together or they are correlated.
There exist 3 metrics(support, confidence, lift) when we try to find the pattern: how many instance support our rule(by calculating how often the items appear together), how confident we are for patterns observed (by calculating the given probability of the rules), and how much the items are related.
Method
This part will show the workflow of training the model with the method introduced before.
Data Selection
The features we use is shown below. As mentioned before, I only choose the description of the positive instances.
Code
import pandas as pdfrom nltk.tokenize import word_tokenizefrom apyori import aprioriimport networkx as nx from nltk.corpus import stopwordsimport matplotlib.pyplot as plt# read the datadf=pd.read_csv("../../data/01-modified-data/cleaned_supervised_data.csv")df=df[df["label"]==1]df["description"].fillna("",inplace=True)#replace the s(which is 's originally) and the t(which is 't originially) and re df["description"]=df["description"].str.replace(" s","")df["description"]=df["description"].str.replace(" t","")df["description"]=df["description"].str.replace(" re","")df["description"]=df["description"].str.replace(" w","")#drop "us" since the stopwords don't include itdf["description"]=df["description"].str.replace(" us","")# drop the stopwordsdef drop_stop(word_list):return[word for word in word_list if word notin stopwords.words('english')]df["description"]=df["description"].apply(word_tokenize)df=df["description"].apply(drop_stop)df.head()
In this part, three functions are firstly defined, calculating the metrics, transforming dataframe to the structure suitable for building network and visualizing respectively.
Code
def reformat_results(results): keep =[]for i inrange(0, len(results)):for j inrange(0, len(list(results[i]))):if (j>1):for k inrange(0, len(list(results[i][j]))):if (len(results[i][j][k][0]) !=0): rhs =list(results[i][j][k][0]) lhs =list(results[i][j][k][1]) conf =float(results[i][j][k][2]) lift =float(results[i][j][k][3]) keep.append([rhs,lhs,supp,conf,supp*conf,lift])if (j==1): supp = results[i][j]return pd.DataFrame(keep, columns =["rhs","lhs","supp","conf","supp x conf","lift"])def convert_to_network(df):print(df)#BUILD GRAPH G = nx.DiGraph() # DIRECTEDfor row in df.iterrows():# for column in df.columns: lhs="_".join(row[1][0]) rhs="_".join(row[1][1]) conf=row[1][3];#print(conf)if(lhs notin G.nodes): G.add_node(lhs)if(rhs notin G.nodes): G.add_node(rhs) edge=(lhs,rhs)if edge notin G.edges: G.add_edge(lhs, rhs, weight=conf)return Gdef plot_network(G):#SPECIFIY X-Y POSITIONS FOR PLOTTING pos=nx.random_layout(G)#GENERATE PLOT fig, ax = plt.subplots() fig.set_size_inches(15, 15)#assign colors based on attributes weights_e = [G[u][v]['weight'] for u,v in G.edges()]#SAMPLE CMAP FOR COLORS cmap=plt.cm.get_cmap('Blues') colors_e = [cmap(G[u][v]['weight']*10) for u,v in G.edges()]#PLOT nx.draw( G, edgecolors="black", edge_color=colors_e, node_size=2000, linewidths=2, font_size=8, font_color="white", font_weight="bold", width=weights_e, with_labels=True, pos=pos, ax=ax ) ax.set(title='Account Description of Users Sending rumors') plt.show()results =list(apriori(df, min_support=0.02, min_confidence=0.2, min_length=3, max_length=2))pd_results = reformat_results(results)G = convert_to_network(pd_results)plot_network(G)
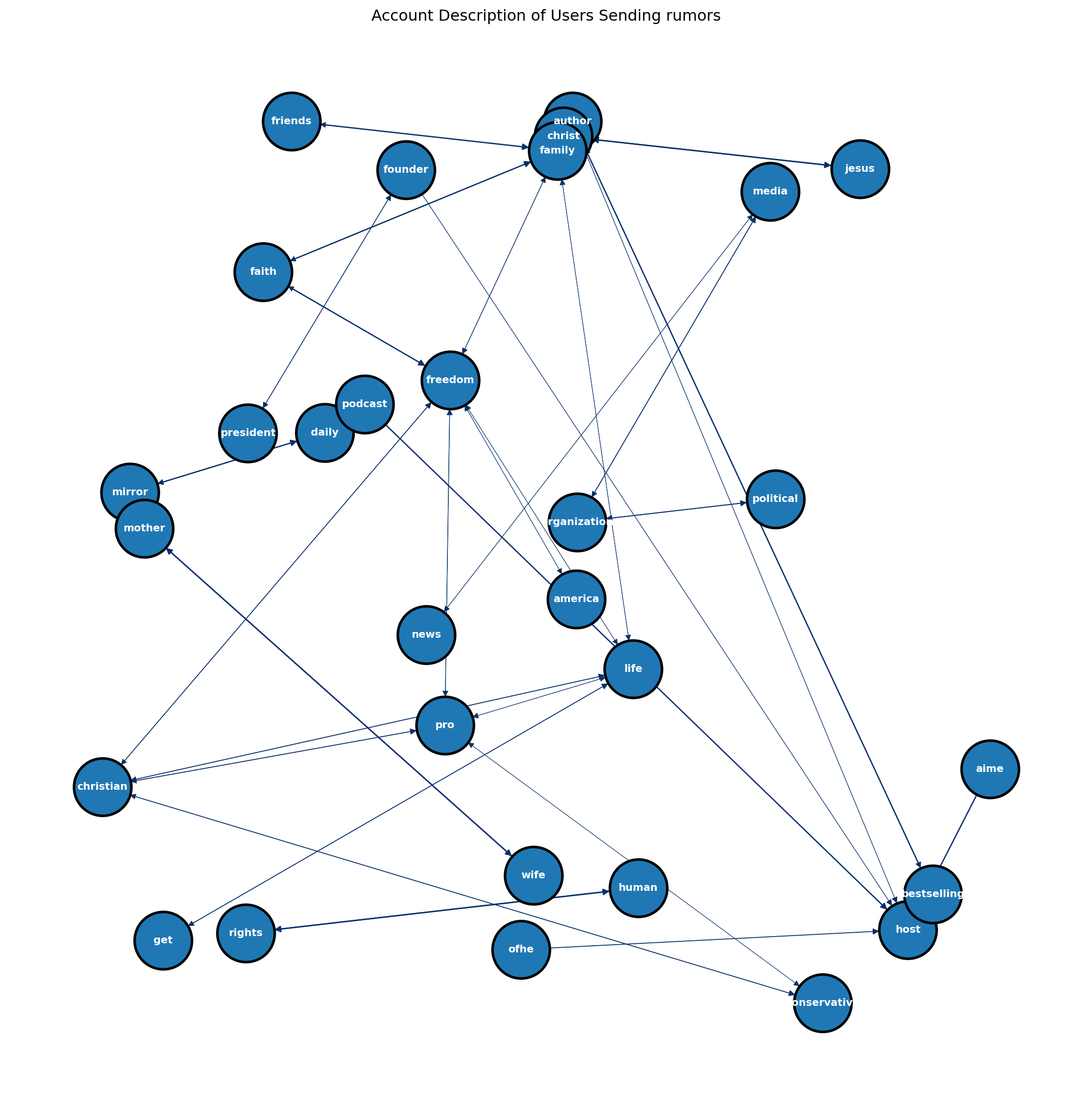
The result include some common sense things, like “christ” appears with “jesus”, “conservative” appears with “christian”.
However, there also exist some inspiring findings. “Political” appears with “organization”, meaning that the account tend to describe it as political organization, by reading the original data, this kind of organizations are the ones sending political information. That is align with the results of EDA, which shows that political topic is the main content of rumors.
Besides,“family”,“life” and “freedom” appear together. Unfortunately, by reading the original data, this represent the core value of many users sending rumors.
Conclusion
In this tab, apriori algorithm has been applied to analyzing the account description written by users who have sent rumors, to do mine the association rule.
The findings are that this kind of users may be an orgainzation sending political information, and they may underline the importance of a combination of family, life and freedom.
Reference
[1]Remanan, S. (2018, November 2). Association rule mining. Medium. Retrieved December 2, 2022, from https://medium.com/towards-data-science/association-rule-mining-be4122fc1793